
近日,处理器芯片全国重点实验室智能计算机研究中心团队关于晶圆级芯片设计和多芯粒全同态加密加速器的三篇论文《ConBin: A Performance-Convergence Framework for Wafer-Scale Chip Binning》、《Unlocking Pipeline Parallelism for Bootstrapping: A Pipelined Multi-Chiplet TFHE Accelerator》、《AutoFHE: An Automatic Hardware Generation Framework for Domain-Specific FHE Accelerators》被计算机体系结构领域顶级会议ISCA 2026(International Symposium on Computer Architecture,CCF-A类)录用。
论文
《ConBin: A Performance-Convergence Framework for Wafer-Scale Chip Binning》
该论文第一作者是实验室智能计算机团队博士生许慧卿,指导老师为王颖研究员、韩银和研究员、王梦迪特别研究助理。针对晶圆级芯片(WSC)制造故障带来的芯片间性能差异大的问题,研究团队提出了一种面向WSC分级的性能收紧框架ConBIN。传统芯片分级方法依据频率或核心数,但WSC的制造故障呈空间分布,这会破坏通信路径并使性能由通信主导,致使传统分级方法失效。此外,芯片间故障分布的不同导致芯片间性能差异显著,迫使分级阈值趋于保守,从而限制了高端芯片的良率与总可销售有效算力(SECC)。为此,研究团队提出以实际负载性能作为分级依据的新范式,并设计了性能收紧框架ConBIN。在硬件层,采用故障空间相关性感知的冗余互连自动化设计,近似规则网格拓扑,以抑制芯片间结构性差异。在软件层,通过芯片分级感知的任务映射与细粒度通信调度优化通信拥塞,在提升平均性能的同时收紧性能分布。最后,基于动态规划算法确定最大化SECC的最优芯片分级阈值。实验表明,在128x136规模的WSC上,相比先进方案,ConBin将高性能芯片良率提升2.80倍,SECC提升2.64倍。该工作通过驱动性能收敛将相同的WSC制造良率转化为更集中的高性能芯片产出,为WSC的大规模商业化提供了可行路径。
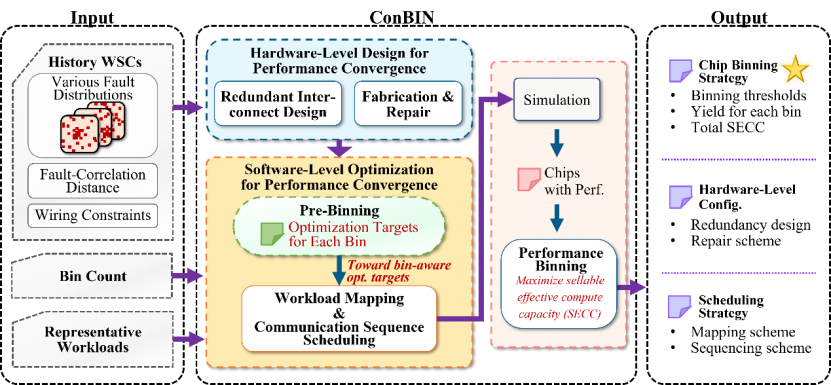
ConBIN性能收敛与芯片分级框架图
论文
《Unlocking Pipeline Parallelism for Bootstrapping: A Pipelined Multi-Chiplet TFHE Accelerator》
该论文第一作者是实验室智能计算机团队博士生杜一博,指导老师为王颖研究员、韩银和研究员、王梦迪特别研究助理。针对 TFHE (一种环面全同态加密方案)中 HMUX 串行数据依赖强、流水线并行下并发 BSK 访问(BSK 为一种密钥)带来的极端内存带宽压力问题,现有基于集中式内存架构的 TFHE 加速器难以承受高并发 BSK 访问,无法充分发挥流水线并行潜力,导致整体执行效率受限。为此,本论文提出了一种分布式多芯粒全同态加密加速器,通过流水线并行架构提升隐私计算效率。在架构层,本文设计了分布式SRAM 内存结构,并提出 BSK-distributed 策略,将原本集中的并发 BSK 访问分散到各个芯粒。结合芯粒间流水线执行模型,BSK 访问主要在芯粒内部完成,从而减少BSK访问冲突并缓解内存带宽压力。在部署层,为实现 TFHE 任务在大规模分布式芯粒系统上的高效部署,本文提出了一个交织融合策略与一个离线调度器,有效挖掘全同态加密内部流水线并行性,最终实现了可扩展的全同态加密计算系统。实验结果表明,本文提出的分布式多芯粒全同态加密加速器能够有效释放全同态加密内部流水线并行潜力,在缓解内存带宽压力的同时,实现高吞吐、可扩展的隐私计算加速,并在 TFHE 应用上相比现有最先进 TFHE 加速器取得了 3.1×∼30.5× 的性能面积比提升。
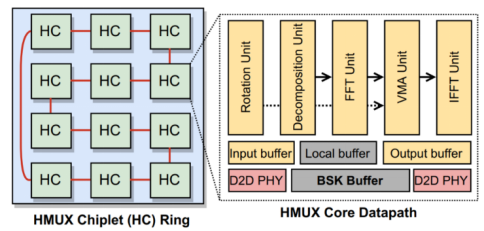
CASCADE多芯粒全同态加密加速器硬件架构图
论文
《AutoFHE: An Automatic Hardware Generation Framework for Domain-Specific FHE Accelerators》
该论文第一作者是实验室智能计算机团队博士生杜一博,指导老师为王颖研究员、韩银和研究员。针对全同态加密处理器设计流程复杂、设计门槛高的问题,现有全同态加密处理器的开发通常需要设计者同时具备密码学与计算机体系结构的复合背景知识,不仅需要手动完成微架构设计,还需要深入理解密文计算逻辑与底层硬件映射关系,导致全同态加密处理器的设计高度依赖少数领域专家,难以实现高效开发与广泛推广。为此,该论文提出了 AutoFHE,一个面向领域专用全同态加密处理器的自动化设计框架,旨在将复杂的全同态加密处理器设计流程转变为普通硬件设计者也能够完成的自动化设计流程。在设计层,AutoFHE 提出了一种基于 Chisel 的密态电路设计语言,并利用 Chisel Annotation 机制实现声明式加密信号标注,使设计者能够以常规方式描述硬件架构,仅需额外标注加密信号。随后,框架自动追踪加密信号在电路中的传播路径,识别所有涉及密文计算的底层硬件模块,并自动将其映射为对应的密文处理单元。AutoFHE 进一步结合密文处理单元虚拟化与设计空间探索,在满足设计约束的前提下自动生成高性能全同态加密处理器。整个自动化流程在 FIRRTL 中间表示层完成,对上层设计者基本透明,从而显著降低了全同态加密处理器的设计复杂度与开发门槛。
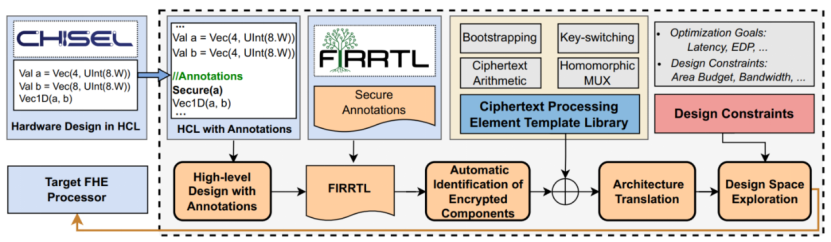
AutoFHE全同态加密处理器自动化设计框架图
ISCA 2026
ISCA是计算机体系结构领域的国际顶级会议,主要聚焦处理器体系结构、存储系统、片上网络、并行与分布式架构、AI加速器、数据中心架构以及软硬件协同优化等方向的前沿研究。自1973年创办以来,ISCA长期代表着全球计算机体系结构研究的最高学术水平,被广泛视为该领域的旗舰会议。ISCA 2026会议的录用率约为19%,本届会议将于2026年6月在美国罗利市举办。
处理器芯片全国重点实验室依托中国科学院计算技术研究所,是中国科学院批准正式启动建设的首批重点实验室之一,并被科技部遴选为首批 20个标杆全国重点实验室,2022年5月开始建设。实验室学术委员会主任为孙凝晖院士,实验室主任为陈云霁研究员。实验室近年来获得了处理器芯片领域首个国家自然科学奖等6项国家级科技奖励;在处理器芯片领域国际顶级会议发表论文的数量长期列居中国第一;在国际上成功开创了深度学习处理器等热门研究方向;直接或间接孵化了总市值数千亿元的国产处理器产业头部企业。
处理器芯片全国重点实验室
实验室聚焦处理器芯片的能效墙、设计墙和指令集墙等核心科技问题,系统性发展相关领域的理论、技术、工具和原型芯片,推动处理器芯片科技研究的体系化发展。









