

(文/朱秩磊)去年10月7日,美国政府宣布了限制向中国出售半导体技术及设备的全面新措施,将此前要求AMD、英伟达断供高端GPU芯片的指令正式化,意图将中国半导体彻底锁死在14nm节点。尽管目前国内已成长起来多家GPU、GPGPU、AI芯片明星企业,部分产品开始逼近甚至超过了美国头部厂商的性能,但他们的产品不全是依靠国内技术积累形成的,而是大量采用了国外(美国)的技术,IP和人员,并且依赖台积电的先进制程代工,更存在IP授权不可控的风险。
值得注意的是,一方面美国针对高性能处理器实施进口封锁,阻碍国内AI、超算产业发展,另一方面英伟达一直对当前GPU主流的编程平台CUDA采取闭源的策略,使得其他硬件开发者难以涉足CUDA所占据的领域。
我国在坚定不移地发展强大的自主可控高性能芯片的目标下,开源架构是否有希望成为一条创新路径?
国产CPU发展之路对GPU的思考和借鉴
CPU和GPU的发展有很多偶然条件,早期英特尔是一家存储厂商,其转型做CPU芯片收获了巨大的成功;英伟达的GPU卡早期主要用于图形游戏市场,在人工智能的第二次浪潮下,成为全球伟大的人工智能芯片厂商;ARM架构处理器来自于英国,主要应用于终端计算产品,借助智能手机的发展,占据了全球95%手机、平板等终端市场的份额。
全球IT市场已形成Windows+Intel(Wintel)、Android+ARM(AA)的主流生态,并且ARM架构的触手正不断延伸至x86架构的领域。
数字化时代,为实现计算芯片的自主可控,十五期间,国家启动发展国产CPU的泰山计划,863计划也提出自主研发CPU。2006年核高基专项启动,国产CPU迎来了新一轮的国家支持,以龙芯、飞腾、鲲鹏、海光、兆芯、申威等为代表的国产CPU厂商崛起。通过多年的耕耘,在国际环境、产业政策、市场需求的联合驱动下,上述国产CPU厂商在性能、工艺、生态建设等多个层面不断取得突破,为CPU的自主可控、安全可信构筑了堡垒。
但是也必须承认,目前国产CPU的应用仍然主要集中在安全、涉密等信创市场,与国外厂商在性能、制造和生态建设等方面都还存在不小差距,在底层协议、技术标准、架构等基础环节仍然大多数由国外IT巨头牢牢把握,平时使用会面临诸多安全风险,国际形势动荡则容易受到美国的制裁打压。
国产CPU多路出击固然展现了中国信创产业的创新能力,但也在很大程度上分散了资源和市场,为硬件适配、操作系统和应用软件的开发带来了困难,而国产GPU(主要是GPGPU)的发展必然也会面临相似局面。
首先是市场空间的限制。一方面,美国禁令影响的高端GPU市场占比不高,但是很关键;另一方面国产GPU进入主流消费市场门槛过高,只能走政府扶持的道路。受国产政策和市场驱动,国内催生了众多的GPGPU初创企业,现实原因这些企业的起步大概率也是通过信创市场,这就要找到一个或若干个地方政府的支持,进而步CPU后尘形成碎片化、分散的市场格局。
其次是人才资源的限制。众所周知,GPU从产品到生态的构建需要具备多学科领域的专业团队协作,包括但不限于图形学、算法、硬件架构、软件架构、系统架构、硬件数字开发、验证、模拟开发、后端、版图、系统、软件、驱动、测试、机械结构、生产等等众多领域的专家。一拥而上的GPU创业团队必然会分食掉原本就十分有限的人才资源。
最后是软件生态的限制。由于市场及客户的碎片化,以及应用端系统的封闭性,国内GPU公司很大一部分工作重心需要用于各种AI平台的适配。如果要能适应所有软件,需要自己开发所有的工具链,这意味着巨大的人力、资金、时间投入,在市场空间有限且客户是否愿意为此买单的情况下,企业生存必定会陷入困境。英伟达在GPU领域实现垄断的原因之一是其CUDA生态足够丰富,国产GPU想要重头建立一个新的生态,对下游开发者将会是非常高风险的选择;但如果完全基于CUDA生态进行开发,那国产GPU的硬件更新将完全绑定英伟达的开发进程,这样就失去了主动性,且永远慢人一步。
可以预见,在上述种种限制下,国产GPU将会在有限市场内陷入各自跑马圈地内卷的局面,而且只有打败了国内这些对手,胜出的企业才有机会去跟英伟达或AMD竞争。
在CPU领域,RISC-V正凭借着兼备开源开放和自主可控等优点,成为越来越多国产CPU的最佳选择。那么在GPU领域,开源架构是否也能帮助中国厂商突破英伟达和AMD长期以来把持的闭源防线?
RISC-V开源架构打造GPU的可行性
近几年在地缘政治抬头趋势下,芯片架构开源的好处显而易见:民主、透明、自由、适应性强,开源让商业IP和工具有一个强大而充满活力的市场,RISC-V的迅速繁荣证明了这一点。市场研究机构Semico Research Group预测,到2025年基于RISC-V架构的处理器核心将超过624亿颗,2018-2025年的年复合增长率高达146%。此外,RISC-V基金会的数据显示,该社区会员数量在70个国家/地区已超过3180名,全球有数万名工程师致力于RISC-V开发项目。
看起来,打造一个有别于英伟达和AMD的开源GPU生态的前提已经满足,即一个自由可获得的指令集架构,以及能够吸引广泛的开发者。现在的问题是,开源GPU,RISC-V已经准备好了吗?
去年一月,英特尔表态投入10亿美金打造RISC-V创新基金,表态支持RISC-V发展;8月阿里平头哥正式发布高性能无剑600 RISC-V芯片设计平台,主打高性能、高内存带宽、异构计算和人工智能加持,推动RISC-V芯片主频从1Ghz走向2Ghz;9月,SiFive成为NASA即将推出的高性能航天计算 (HPSC) 处理器提供核心CPU的供应商,用RISC-V架构的芯片搭建要求极高的航空领域的高性能处理器;最近Ventana宣布推出了Veyron系列高性能RISC-V处理器,采用高性能Chiplet和IP的形式提供……
种种迹象表明RISC-V已经从低算力的智能物联技术向桌面级、边缘计算渗透,并继续迈向HPC,大规模计算场景进军。如果说走向高性能是基于RISC-V打造开源GPU的设想开始,那2021年9月RISC-V向量扩展(RVV)1.0的正式推出则使得这一设想有了底层技术的支撑。

从左至右:上海清华国际创新中心集成电路研究平台主任助理程宝忠;清华大学集成电路学院副教授、上海清华国际创新中心集成电路研究平台副主任何虎;清华大学集成电路学院、承影团队杨轲翔
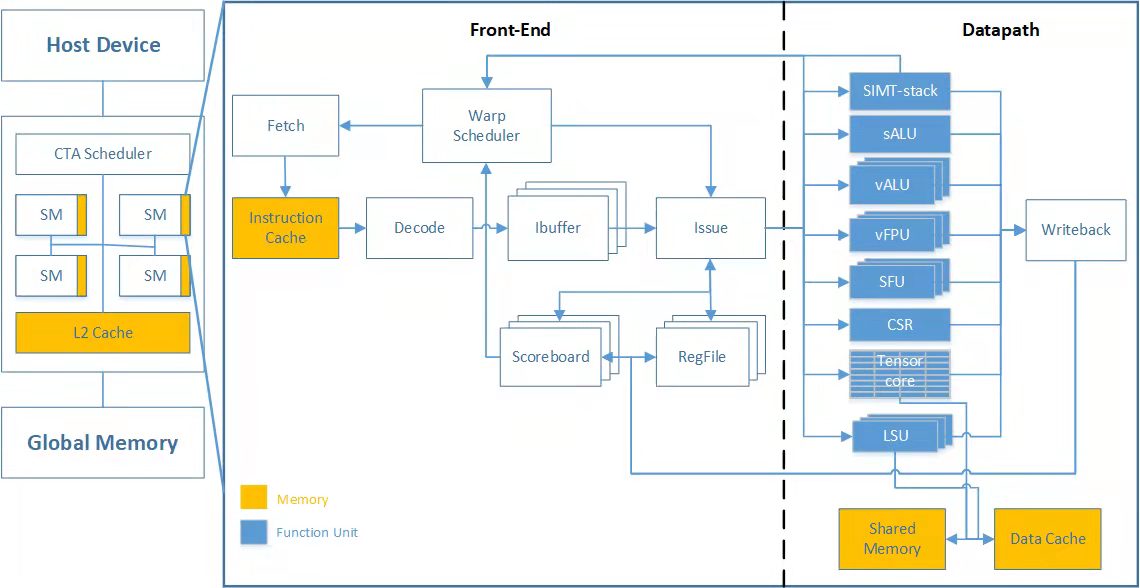
清华大学集成电路学院副教授、上海清华国际创新中心集成电路研究平台副主任何虎团队的新项目就基于开源指令集+开源软件工具链+开源硬件架构创新,将GPGPU并行计算与传统CPU的串行计算优势进行整合,为国内GPGPU的发展提供了一种新的思路。在去年8月,何虎团队发布了首款基于RISC-V向量扩展(RVV)的GPGPU“Ventus(承影)”,也是国内首个开源GPGPU,通过RVV+OpenCL编程框架+Tensor Core张量计算单元,为国内学术界和工业界提供技术路线评估和平台搭建基础的参考,在后续协同企业开发国产全自主GPU商用产品路上迈出关键一步。
承影基于GPGPU编程模型进行设计,采用RISC-V向量扩展,基于LLVM开源工具链完成GPGPU编译器的开发,支持OpenCL开源并行编程框架。同时,RVV GPGPU参考RISC-V CPU开发思路,在满足SIMT基础功能的同时,汲取了RISC-V向量扩展在功能定义和指令设计上的优势,并将二者有机结合,使得承影同时具备向量处理器工具链兼容性和GPGPU编程灵活性,未来也能更好结合RISC-V编译器、打造统一指令集SoC系统。
据分析,从软件编程模型来看,承影通过驱动程序和CTA Scheduler来进行GPGPU的任务分发,然后各个流多处理器(Streaming Multiprocessor,SM)核以类似于RISC-V处理器的模式进行计算,这样带来两个非常大的优势,一是可以建立在RISC-V生态基础上,不需要完全重新建立GPU生态,规避了与CUDA的专利问题;二是每个SM核的独立性更好,可以执行比常规GPU CUDA核更复杂的计算。
在去年8月发布之时,承影已经在Xilinx VCU128 FPGA上完成了验证,团队开发了AXI驱动程序,并用MicroBlaze作为Host进行任务发射,用PL搭建“承影”GPGPU进行计算,通过DDR共享内存。按照4 warp 8 thread的配置可部署160个核心,核心频率为100MHz,理论峰值算力为32Gflops,可同时驻留1280个线程。(点击了解承影GPGPU:https://github.com/THU-DSP-LAB/)
团队成员杨轲翔坦言,第一版的承影还是一个很简略的版本,很多功能都没有,但是已经在国内GPU圈子产生较大的影响力,让大家知道清华大学、上海清华国际创新中心在做这个事情。团队将在2023年8月推出承影GPGPU2.0版本。届时承影GPGPU将实现一个完整的GPGPU设计,并包括完整的工具链。
开源GPU还需解决的难题
在清华大学开源GPGPU项目承影之前,其实全球范围内已有多个机构发布过类似的项目,比如英属哥伦比亚大学的GPGPU-Sim,威斯康星麦迪逊大学的MIAOW GPGPU,乔治亚理工学院的Vortex GPU等,基本都是高校的研究项目,RISC-V的GPU生态发展尚属初期,真正商业化落地还需要解决不少难题。
第一,是开源GPU设计的先进性。要用开源的指令集来开发出一个开源、开放的GPGPU,设计必须要具备足够的先进性,也要有适用的应用场景,才能给行业以信心,吸引更多生态合作伙伴的参与。而当前已公开的开源GPU项目,仍然以追赶、对标当前主流甚至几年前的GPU产品的性能为目标。由于开发资源、积累时间的限制,开源GPU与商用GPU还有着不小的性能差异,能够进入量产也还为时尚早。

对此,承影在接下来的版本更新中会不断增加定制修改,同时会加入一些专项设计单元以及配套的软件库。杨轲翔举例说,当前通用架构下的芯片性能对于各类人工智能所需的数据量和算力越来越难以满足,在这样的背景下,诞生了张量计算单元(Tensor Core)等专为人工智能定制的计算单元。将这类领域定制架构与已有的RISC-V GPGPU架构进行结合,就可以提升峰值算力,也能在功耗、运算速度等方面增加优势。他透露,除了张量计算单元,后续还会考虑针对Transformer等新兴网络架构进行适配。更长期的目标则是加入图形渲染功能,比如光线追踪等。
第二,敏捷开发语言Chisel已经在RISC-V处理器设计中很常见,承影使用了Chisel HDL实现,中科院另一款香山开源处理器也是用Chisel编写的。然而,Chisel仍然没有被工业界普遍接受,这是由于要学习Chisel编程语言需要一定的面向对象编程基础和函数式编程经验,上手门槛高,可读性也差一些;其次使用Chisel进行设计,优化的空间相对较小;最后主流的EDA工具对Chisel支持还不多。
第三,开源GPU设计工具链、软件生态支持仍然稀缺。比如当前承影主要软件工具链包括支持OpenCL编程框架的编译器(kernel),支持OpenCL编程框架的驱动程序 (platform),承影自身的周期精度仿真器。而完整的软件工具链需要比硬件开发更为庞大的人才团队支撑,这仅仅依靠一个小型的高校研究团队或者单独几家公司是无法实现的,需要产业多方的合作。
写在最后
GPU其实是一个很复杂的产品,不是简单的硬件开源以后就可以直接为大家使用,必须要有相应的SDK和软件,这些软件和SDK的开发是否是开源硬件同来源的公司提供?优化做得如何?是否能完整地支持各种不同的接口,各种Open GL,有没有通过相应的一致性?这些都是很复杂而艰巨的工作,绝对不仅仅是一个开源GPU开出来,大家就可以用了,开发的过程还远远没有完成,挑战仍然艰巨。
不过清华大学承影项目,仍然是一次GPGPU与RISC-V生态结合的积极探索,对促进国产GPU的发展有重要意义,为当前陷入困境的国产高性能芯片研发开辟了一个新天地。我们希望它能在国内树立一个开源生态示范,召集、建立起开放的上下游生态,建设积极旺盛的人才培养环境,使部分国内GPU设计公司核心技术摆脱海外IP授权,打破行业垄断玩家对先进技术的封锁。
(校对/杜莎)








