
近日,深圳市迈特芯科技有限公司(迈特芯)及南方科技大学微电子学院研发团队在具身智能硬件领域取得多项突破性成果:首先在芯片方向,团队成功流片验证了立方脉动架构,面向具身深度学习网络,通过网络搜索优化,实现了最优的能效比(29.12 TOPS/W)和面积比(7.94 TOPS/mm2)。同时在加速卡方向,团队研发的具有立方脉动架构端侧大模型推理卡,成功实现了大语言模型(LLM)在边端部署,达到了近80%带宽利用率(75tps)。在系统应用方向,团队将LLM加速卡实体化到边缘侧的下一代测序仪,实现了实时现场进行智能基因诊断。
具身智能芯片
随着大模型时代的到来,深度神经网络模型的算力需求呈指数级增长,但传统芯片架构面临能效与性能的双重瓶颈。研究团队针对这一挑战突破传统AI芯片设计中“能效-面积-灵活性”三角矛盾,实现了三大技术创新:
动态精度调控:打破固定精度限制,在能效与准确率间实现动态平衡;
结构化稀疏编码:通过对数尺度稀疏策略,在压缩率提升30%的同时保持模型精度;
矢量脉动阵列:创新的脉动架构将内存带宽利用率提升至92%,显著降低数据搬运能耗。


图1 混合精度加速器芯片及混合稀疏加速器芯片图
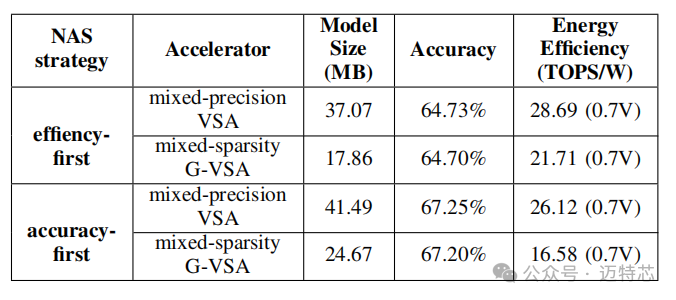
图2 具有混合精度及稀疏的立方脉动架构芯片的性能比较
该成果发表在集成电路设计领域顶级期刊IEEE Journal of Solid-State Circuits
具身智能加速卡
研发团队进一步攻克大语言模型(LLM)在资源受限边缘设备上的部署,利用已验证的混合精度计算单元以及立方脉动阵列架构,成功部署了多个7B LLM语言模型及多模态模型。与GPU相比,该系统的吞吐量提高了1.91倍,能效提高了7.55倍;与最先进的FPGA加速器FlightLLM相比,整体性能提升了10%到24%。
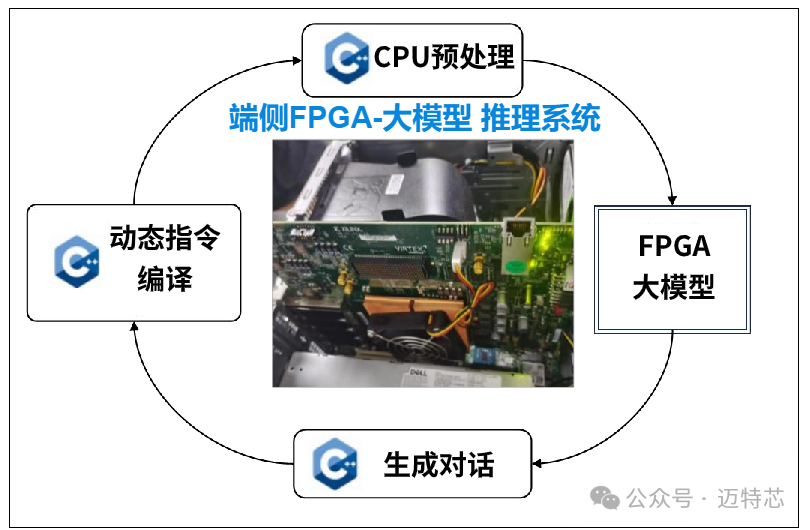
图3 端侧大模型推理卡
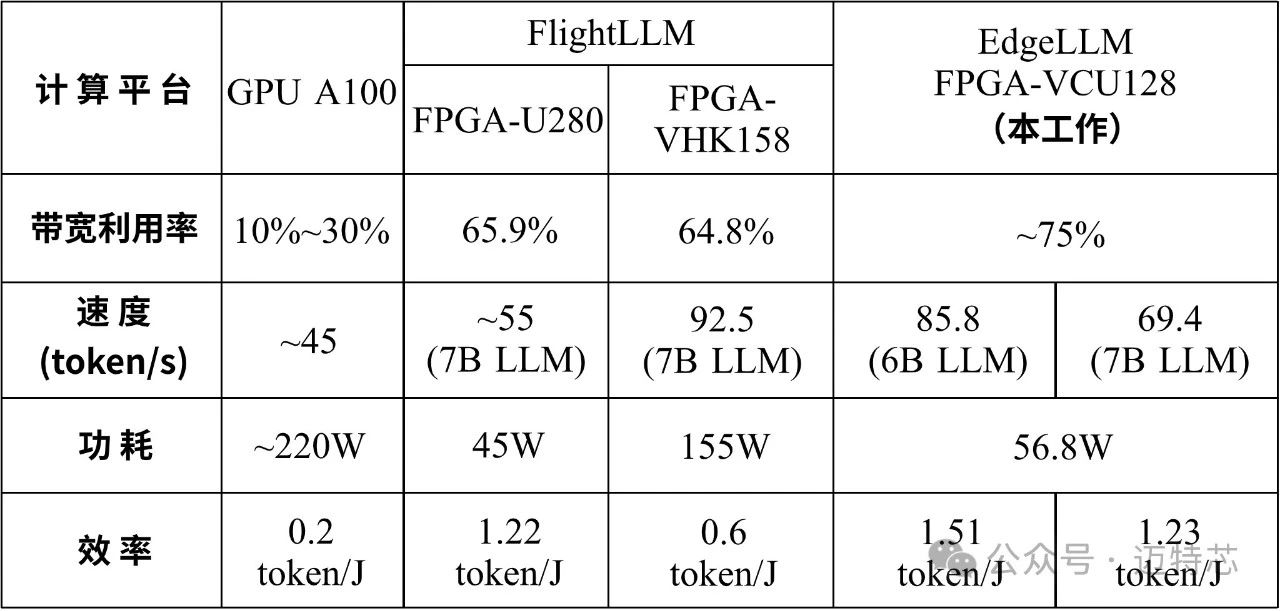
图4 不同端侧大模型推理卡对比
该成果发表在电路与系统领域顶级期刊 IEEE Transactions on Circuits and Systems I: Regular Papers。
具身智能系统应用落地
作为端侧大模型推理卡应用,团队和上海芯像生物科技有限公司合作研发了LLM具身化的NGS测序仪-emGene,优化后的大语言模型得以在端侧大模型推理卡上高效部署,使诊断流程大幅提速,从而实现实时、现场DNA分析,在医疗领域实现实时、现场基因智能诊断的实际应用。
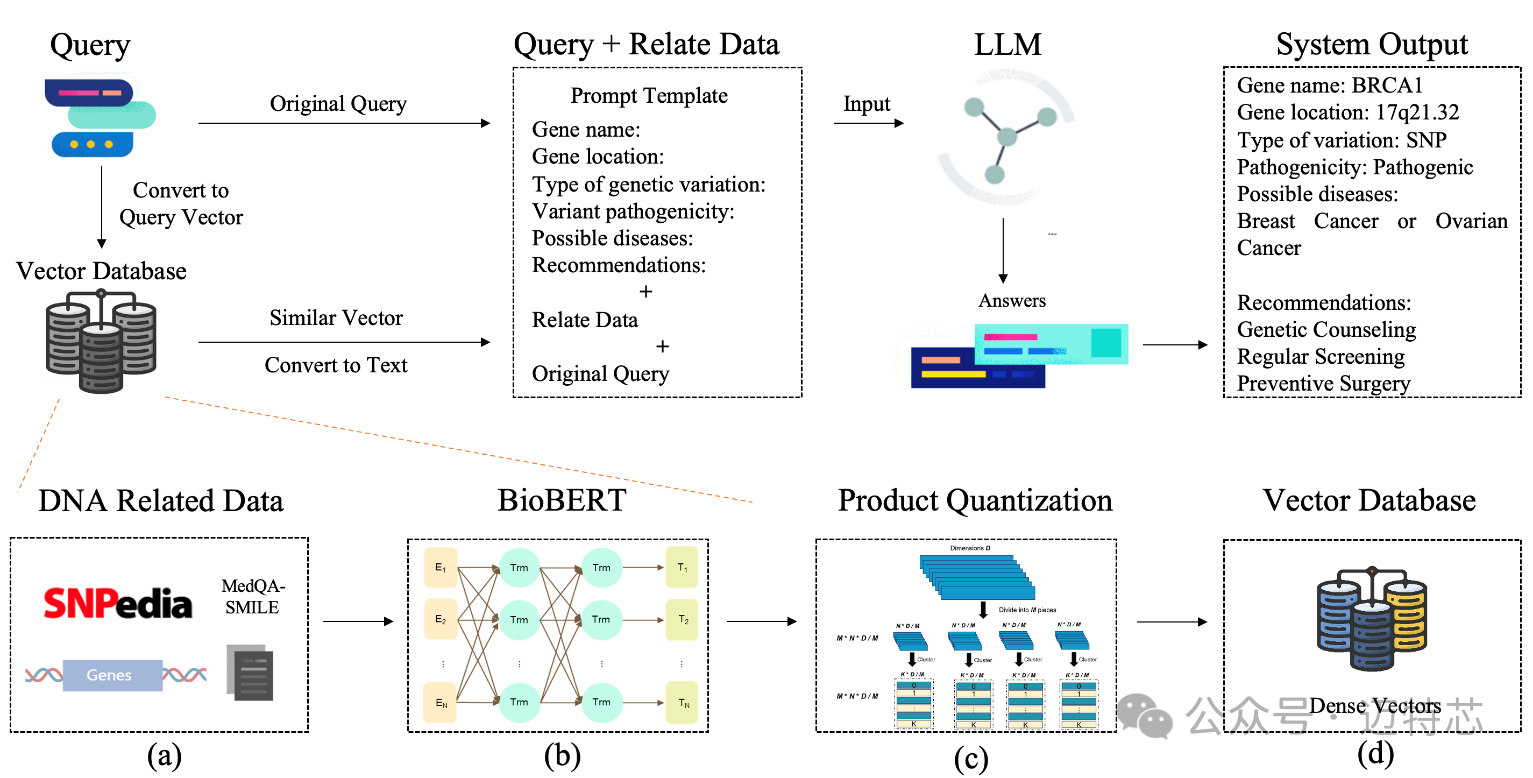

图5 emGene大语言模型(LLM)边缘NGS测序仪
该成果发表在电路与系统领域顶级期刊IEEE Integrated Circuits and Systems。









