
科研进展
随着现代科学与工程计算需求的增加,常微分方程(ODE)在物理学、气候建模和人工智能等领域扮演着核心角色。然而,传统基于冯·诺依曼架构的硬件在求解这些方程时面临速度和能效瓶颈。为此,研究者们探索新型硬件架构,忆阻器因其优越的能效和并行处理能力成为理想选择。目前,虽然基于忆阻器的偏微分方程(PDE)求解器已有显著进展,但直接应用于ODE求解仍面临挑战。为了确保合适的精度,往往需要进行大量的设备重新编程或者高消耗的计算资源,这不仅增加了系统的复杂性,还限制了其在实际应用中的可行性。因此,开发高效且精确的ODE求解器成为当前的研究重点。
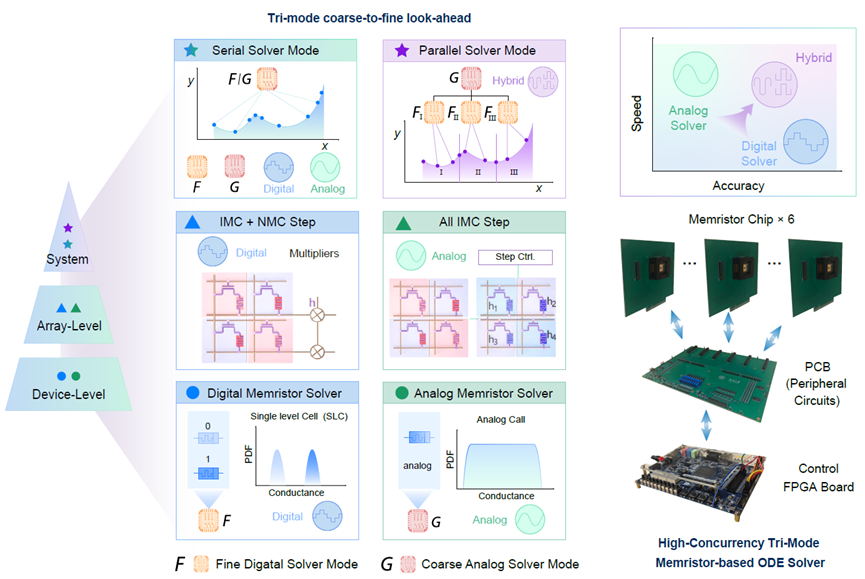
图1: 高并发三模式ODE求解器可以应对不同精度和速度需求的ODE问题
针对这一关键难题,北京大学杨玉超教授团队首次提出了一种高并发的基于忆阻器的三模式ODE求解器,该求解器通过高效的软硬件协同设计和创新的编程和计算方法,无需重复编程即可求解任意ODE系统,大幅提升了求解速度和能效。该工作创新性地提出了基于忆阻器的三模式求解框架,结合了粗略求解、精细求解以及粗细混合的前瞻性求解模式,极大提升了并行处理能力和计算效率。为了进一步提升求解精度和计算效率,研究团队还提出了基于历史的忆阻器编程方案(History-based Memristor Programming, HMP),通过优化写入过程,显著提高了设备编程速度,同时保持了出色的精度。此外,团队还设计了存内步长计算方法,利用忆阻器阵列实现了步长自适应控制,存内一次性完成步长计算,避免了传统方法中频繁的外部计算和存取,极大降低了能耗和计算延迟。这一创新方案推动了存算一体ODE求解硬件系统的性能突破,使得在复杂ODE任务中能够实现高效的并行计算。
该系统基于实际流片的忆阻器芯片,结合PCB与FPGA搭建了端到端的应用演示平台,全面验证了其在典型ODE求解任务中的优越性能。该系统采用了三种不同的求解模式,以应对不同精度和速度需求的ODE问题。粗求解器利用忆阻器阵列的模拟计算能力,成功求解了指数函数问题,适用于对速度要求较高但精度要求较低的场景。细求解器则通过数字计算,精确求解了洛伦兹方程,能够在保证高精度的同时,较为平衡地控制计算开销。并行求解器则采用了粗细混合的前瞻性求解策略,成功求解了经典的三体问题,通过并行计算大幅提升了求解速度和精度,适用于复杂的高并发任务。实验结果表明,这三种求解模式在不同任务中均表现出了优异的性能,相较于现有的CPU/GPU系统,该系统在三类经典ODE问题上实现了高达601~6.92×103倍的速度提升、1.71×103 ~3.93×103倍的能效提升,充分展示了忆阻器存算一体架构在常微分方程求解中的强大潜力,进一步证明了这一创新架构的前景。
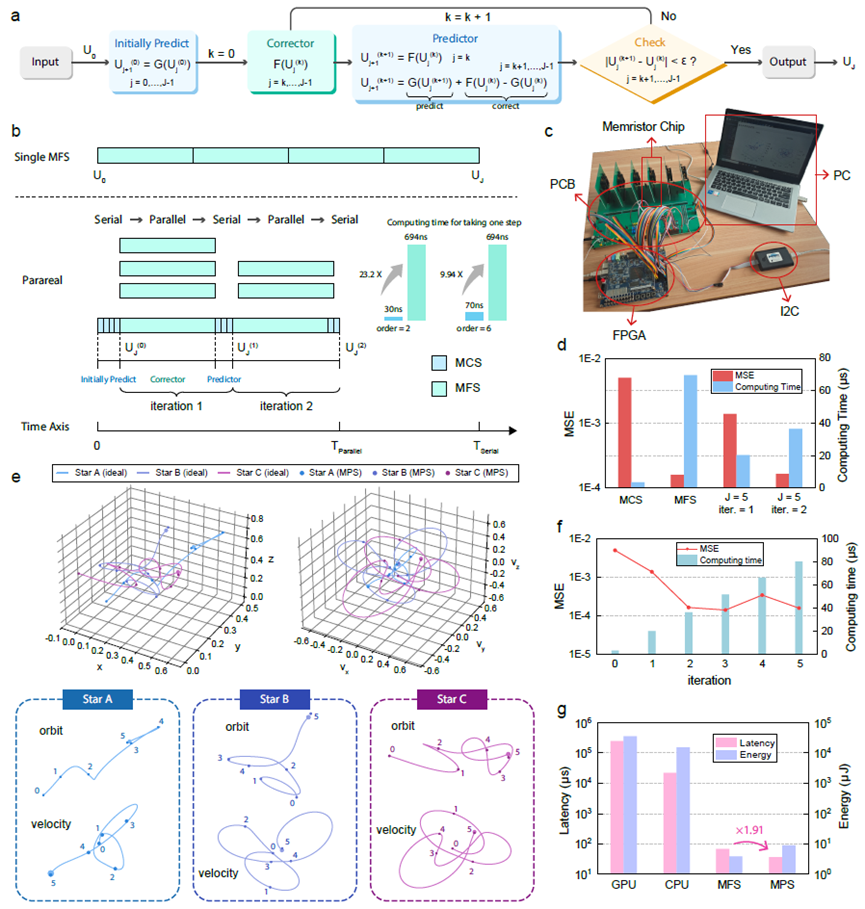
图2: 使用并行求解器模式求解三体问题的实验演示
相关成果以“High-concurrency tri-mode memristor-based ordinary differential equation solver”为题,发表于国际顶尖期刊《自然∙通讯》(Nature Communications)。北京大学集成电路学院博士生余连风为第一作者,集成电路学院杨玉超教授与人工智能研究院陶耀宇研究员为通讯作者。相关工作得到了新基石研究员项目、国家重点研发计划、国家自然科学基金、广东省存算一体芯片重点实验室、北京市自然科学基金等项目的资助。








