

算力集群Scaling Law(尺度规律)还奏效么?万卡级智算集群还是全球AI大模型竞争的“入场券”么?十万卡智算集群仍然是算力备战的目标么?
今年年初,DeepSeek-V3训练只使用了2048张H800GPU的消息传出,像一颗核弹,给长期信奉规模取胜的智能算力市场带来了不小的震憾。智算行业曾经坚信不移的Scaling Law——智算集群规模将沿着千卡、万卡、十万卡顺序部署的路线,也因此产生了动摇。但几个月过去,记者发现,DeepSeek的出现的确给算力芯片市场带来了不小的变化,但业界对尺度规律的认可度仍然坚挺。
推理算力市场迎猛增
毫无疑问,DeepSeek给推理芯片和推理算力市场注入了一针强心剂。
某业内人士表示,2024年,多地建设的智算中心普遍存在空置的现象。但在DeepSeek发布后,各地算力中心资源的利用率实现了大幅提升。
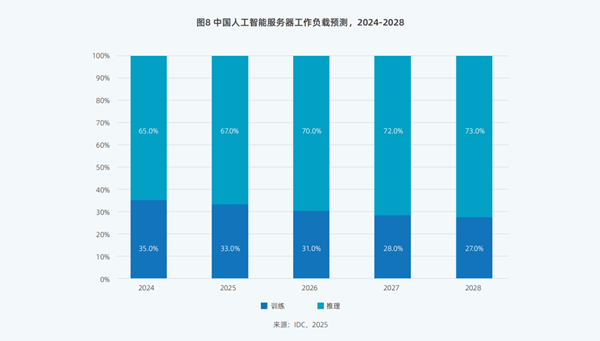
图片来源:2025 中国人工智能计算力发展评估报告
市场分析机构发布数据显示,中国人工智能服务器工作负载中,推理算力的占比将在未来几年大幅增长,预计到 2028 年中国推理算力的市场份额将从2024年的65%增长到73%。
浪潮高级副总裁刘军也表示 :“在 DeepSeek 发布后,推理算力的需求量正在迅速超过训练算力,市场结构发生了根本性变化。”
感受到市场需求的牵引,多家国产算力芯片公司今年将业务发展重点放在了推理领域。例如,今年2月,燧原宣布其庆阳智算中心部署的万卡集群为美图AI推理业务提供算力;今年3月,沐曦科技宣布联合清华大学KVCache.AI团队加速DeepSeek满血版单卡C500异构推理等。
但截至目前,推理市场实际上并不存在对“真万卡集群”的刚需。根据阿里研究院副院长安筱鹏的理解,只有一万张AI加速卡部署在同一个数据中心,并且能通过大规模资源调度技术,让万卡作为“一台”计算机,支持单一模型在一万张卡上同时进行训练,才能被认为是“真万卡集群”。但推理任务更多是分布式实现的,其算力规模需求远低于万卡。[XZ1]
规模定律仍在训练领域奏效
“大模型本地部署有望成为国产算力芯片的重要增长拉动力。” 联通元景大模型负责人在接受《中国电子报》记者采访时如是说。
DeepSeek之所以能撬动巨大的推理算力市场,本质上得益于其底层基础模型V3的高质量训练。而强大的算力,是支撑该模型乃至后续其他模型迭代的基础。
联通云相关负责人介绍,大模型参数规模从千亿级迈向万亿级,训练数据量也呈指数级增长。大规模训练集群能够通过并行计算和分布式处理,显著缩短训练周期,为模型快速迭代提供基础设施支撑。但从当前的情况来看,万卡集群在训练效率上已经不足以支持大模型的迭代速度。而十万卡集群,能够通过更高并行度和分布式优化,在万卡集群基础上实现训练效率的再度提升。
但建设大规模训练集群,仍存在诸多待解的技术问题。多地域部署、多芯混训、集群稳定性都给集群建设带来了挑战。集群稳定性要求高,快速容错和恢复是关键;能耗与散热、数据管理和运维管理等问题同样重要——集群每日能耗甚至将高达300万千瓦时,与一个小型机械厂一年的用电量相当。
在中国联通相关业务人员看来,综合考虑企业需求、行业应用和区域分布,中国可能需要3—5个“真十万卡集群”,这些集群应具备高效能、低能耗、高稳定性的特点,并支持多任务并发和动态资源调度,以最大化算力利用率。
双重路线竞争
可以预见,未来的算力集群部署,将以训练与推理为界,形成巨大分野,呈现出“双轨并行”新格局:
一方面,头部企业持续加码超大规模集群,集中力量实现训练性能突破。
调度方面,百度、腾讯等企业开发了面向超大集群的自动切分、任务容错系统;能源管理上,液冷、浸没式等新型冷却技术成为数据中心标配,PUE(能源利用效率)持续优化;多芯融合层面,一些平台已实现“国产+进口”GPU、NPU、ASIC的调度统一,个别厂商甚至宣布支持六芯异构协同训练。
与此同时,“以训练反哺调度优化”成为技术演进的新方向。通过AI自身参与任务调度、负载均衡,集群可以实现自动化资源编排——这正是AI基础设施向“智能化操作系统”演进的表现。某种意义上,十万卡不再只是“计算力的集合”,而是“算力+AI控制力”的系统体。
“十万卡集群”的比拼,最终将落脚于如何将堆卡用好、用足、用出性价比。
另一方面,各地方、中小企业在智算赛道的着眼点将转向算法高效化与推理优化。越来越多企业开始选择用数百张卡构建私有化小型训练集群,结合开源模型做定制化微调。通过模型蒸馏、芯片定制和边缘算力部署,在特定场景下以更低成本参与竞争,推动AI技术下沉至垂直领域。





评论
文明上网理性发言,请遵守新闻评论服务协议
登录参与评论
0/1000